仕事でネットワーク分析に苦しむ機会が増えてきた。
その中で疎行列 (sparse matrix) を取り扱う重要性が高まってきている。
本稿の目的は疎行列の意義と使い方を学び、仲良くなることである。

疎行列とは
疎行列とは、要素のほとんどが 0 であるような行列のことである。
巨大な行列を用いた計算が必要になることがある。 行列が巨大になるときに問題となるのは、行列がメモリを圧迫することである。
例えば、1万×1万の単位行列を、以下のように適当に作成する。
I <- diag(nrow = 10000, ncol = 10000) pryr::object_size(I)
800 MB
単純な単位行列ではあるが、800 MB ものメモリが割り当てられている。
これが、100万×100万の単位行列を普通に作成すると、以下の通りになる。
I <- diag(nrow = 1000000, ncol = 1000000)
Error: cannot allocate vector of size 7450.6 Gb
たった1つの単位行列を作成するために、7 TB ものメモリーが必要となってしまう。 この行列のほとんどは 0 であるが、それらがわざわざ全て保存される結果、このように巨大な容量を食ってしまう。
ということは、行列の要素がほとんど 0 であるという特性を活かせば、無理なく作成することができるはずである。
そこで疎行列の出番である。RではMatrixパッケージを用いて以下のように作成できる。
I_sp <- Matrix::sparseMatrix(i = 1:1000000, j = 1:1000000) I_sp[1:3, 1:3]
3 x 3 sparse Matrix of class "ngCMatrix"
[1,] | . .
[2,] . | .
[3,] . . |
pryr::object_size(I_sp)
8 MB
100万×100万の単位行列も、わずか8MBで作成できる。 対角要素は全てbooleanで表現されているので、そのおかげでさらにメモリ容量が節約できている。
I_sp[1, 1]
[1] TRUE
これを全て1にすると以下の通りとなり、メモリへの割当が多少増加する。
I_one <- as(I_sp, "dgCMatrix") I_one[1, 1]
[1] 1
pryr::object_size(I_one)
16 MB
行列演算も通常と同じようにできる。 面白くない例だが、疎行列の単位行列を2つ掛け合わせることは以下のようにできる。
I_sp %*% I_sp
ネットワーク分析における疎行列
グラフで誰と誰がつながっているかを表現するために使われる行列を、隣接行列 (adjacency matrix) と呼ぶ。
例えばノードの数が3つで、1 -- 2 -- 3 のようなつながりのある無向グラフは
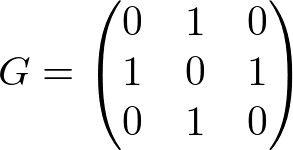
と表現できる。つまりGの(i, j)要素は、ノードiとjの繋がりを表現する。
グラフが小さいときはまだ上のように表現できる。 しかしグラフが巨大になるとメモリを圧迫してしまうのは、上で見た例の通りである。 そこで、多くのグラフは sparse であるという特性を活かし、グラフを疎行列で表現することがよく使われる。
Rでネットワーク分析を行うときによく使われるパッケージ群の1つとしてstatnetがある。
例えば、指数ランダムグラフモデル (exponential random graph model; ERGM) を推定するときは、
networkでネットワークオブジェクトを作成して、それに基づき推定を行う。
以下はその一例である。
library(statnet) data(florentine) est <- ergm(formula = flomarriage ~ edges + absdiff("wealth") + triangle)
しかしそのネットワークに色々と操作を加えるときはそのネットワークを一度隣接行列に置き換えて処理を行う必要が出てくる。 その際にネットワークオブジェクトを隣接行列に置き換えるのは、例えば以下のようなコードがある。
adj <- network::as.matrix.network.adjacency(flomarriage) head(adj[, 1:3])
Acciaiuoli Albizzi Barbadori Acciaiuoli 0 0 0 Albizzi 0 0 0 Barbadori 0 0 0 Bischeri 0 0 0 Castellani 0 0 1 Ginori 0 1 0
しかしどういうわけか、network::as.matrix.network.adjacencyは密行列 (dense matrix) して隣接行列を返す。
これはネットワークが大きい場合、メモリを大きく圧迫してしまう。
それを回避するためには、まずネットワークをedgelist、つまりつながっているノード同士だけを取り出す。
edgelist <- network::as.edgelist(flomarriage)
そこからこのネットワークを疎行列として表現する。
adj_sp <- Matrix::sparseMatrix(i = edgelist[, 1], j = edgelist[, 2], symmetric = TRUE)
pryr::object_size(adj)
3.58 kB
pryr::object_size(adj_sp)
1.82 kB
小さいネットワークだと対した差ではないが、これがノード数が増えると両者の差は爆発的に広がっていく。
Rcppで疎行列をたしなむ
隣接行列を用いた重たい処理が必要なときは、Rの疎行列をRcppに渡して高速化することができる。
ここではRcppArmadilloを用いてやってみる。 やったことはないが、RcppEigenでも同じようにできるらしい。
その処理の例として、ノードiとjのつながりのうち、iとjが同じ特徴量を持つような隣接行列を作ることを考える。 例えば特徴量として性別を考えたとき、同じ性別同士で実際につながっているリンクのみ含んだ隣接行列を作成したい。
まずは適当にグラフを作成し、疎行列で表現する。
# This seed comes from the result of the 2020 Hawks-Giants Japan Series. set.seed(264) # Number of nodes N <- 1000 # Create an edgelist. I consider an undirected network. edgelist <- tibble::tibble(tail = 1:N, head = 1:N) %>% tidyr::expand(tail, head) %>% dplyr::filter(tail < head) %>% dplyr::mutate(connected = as.integer(unlist(purrr::rbernoulli(n = nrow(.), p = 0.01)))) %>% dplyr::filter(connected == 1) # Create a sparse adjacency matrix net <- Matrix::sparseMatrix(i = edgelist$tail, j = edgelist$head, dims = c(N, N), symmetric = TRUE) net <- as(object = net, Class = "dsCMatrix")
次にノードの特徴量を適当に作成する。
# Vertex feature like gender. x <- unlist(purrr::rbernoulli(n = N))
そして今やりたい処理をC++のコードで書く。
RcppArmadilloで疎行列を扱うときはarma::sp_matを用いる。
#include <RcppArmadillo.h> // [[Rcpp::depends(RcppArmadillo)]] // [[Rcpp::export]] arma::sp_mat get_connected_same_feature_dyads_cpp(const arma::sp_mat& adjmat, const arma::vec& feature) { int n_nodes = adjmat.n_rows; arma::sp_mat output(n_nodes, n_nodes); for (int i = 0; i < n_nodes; i++) { for (int j = 0; j < n_nodes; j++) { if (i != j) { if (adjmat(i, j) == 1 & feature[i] == feature[j]) { output(i, j) = 1; } } } } return output; }
実際に実行してみる。
Rcpp::sourceCpp("src/get_connected_same_feature_dyads_cpp.cpp") output <- get_connected_same_feature_dyads_cpp(net, x)
net[1, 996] == 1 & x[1] == x[996]
[1] TRUE
output[1, 996]
[1] 1
正しく計算できているように思う。
別にやる必要はないが、同じ処理をRで実装すると以下の通りとなる。
get_connected_same_feature_dyads_R <- function(adjmat, x) { n_nodes <- length(x) output <- Matrix::sparseMatrix(i = {}, j = {}, dims = c(length(x), length(x))) for (i in 1:n_nodes) { for (j in 1:n_nodes) { if (i != j) { if (adjmat[i, j] == 1 & x[i] == x[j]) { output[i, j] <- TRUE } } } } return(output) }
ベンチマークを行うとRcppの方が圧倒的に速い。Rでforを書いた時点で負け確定であるのは内緒である。
time <- rbenchmark::benchmark( "R" = { output <- get_connected_same_feature_dyads_R(net, x) }, "cpp" = { output <- get_connected_same_feature_dyads_cpp(net, x) }, replications = 1 ) time
test replications elapsed relative user.self sys.self user.child sys.child 2 cpp 1 0.016 1.00 0.016 0.000 0 0 1 R 1 136.508 8531.75 136.516 0.004 0 0
Rを使ってより高速に処理するには一工夫必要なことも多いが、変に凝ったコードを書くぐらいならRcppで殴ってしまった方が良い。
終わりに
ぜひみなさんも疎行列に親しみ、ネットワーク分析に苦しみましょう。